这是个人阅读Effective STL所做的读书笔记第四部分,包含《Effective STL》条款28~条款36的笔记内容。
条款31:了解你的排序选择
- 如果你需要在vector、string、deque或数组上进行完全顺序排序,可以使用sort或stable_sort
- 如果你有一个vector、string、deque或数组,你只需排序前n个元素,应该使用partial_sort
- 如果你有一个vector、string、deque或数组,你需要鉴别出第N个元素或你需要鉴别出最前的n个元素,而你不用知道他们的顺序,nth_element是你应该注意和调用的
- 如果你需要把标准序列容器的元素或数组分隔为满足和不满足某个标准,可以使用partition或stable_partition
- 如果你的数据在list中,由于sort、stable_sort、partial_sort和nth_element需要随机访问迭代器,list无法使用这些方法,list通过提供成员sort方法来作为补偿,而如果需要partial_sort和nth_element提供的效果,你就必须间接完成这些任务。一个间接的方法是把元素拷贝到一个支持随机访问迭代器的容器内,然后应用需要的算法;或者建立一个list::iterator的容器,对那个容器使用算法,然后对它应用需要的算法。
这些算法在时间、空间上资源消耗排序(由少到多):
- partition
- stable_partition
- nth_element
- partial_sort
- sort
- stable_sort
条款32:如果你真的想删除东西的话就在类似remove的算法后接上erase
algorithm中的remove函数签名为:
1 | template <class ForwardIterator, class T> |
由于其接受的为一个迭代器区间,所以remove方法本身并不能调用该迭代器指向的容器的删除元素方法实现真正意义上的删除元素。
remove仅仅把不应删除的元素覆盖赋值到应删除元素的位置,并返回覆盖之后最后一个不应删除元素的后面一个位置。
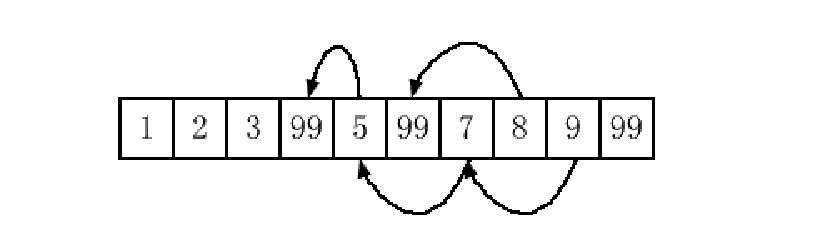
书上这个图阐述了remove的执行过程,因此如果要想真正意义上删除元素可以配合容器的erase来使用,也就是经常使用的erase、remove模式:
1 | vector<int> v; // 正如从前 |
要注意的是list的成员函数remove是直接包含erase和algorithm中的remove两个操作的,也就是list的remove做到了真正意义上的删除元素。
另外algorithm中的remove_if和unique类似于remove并不直接删除元素,而list的成员函数remove_if和unique也类似于list的remove会去真正意义上删除元素。
条款33:堤防在指针的容器上使用类似remove的算法
正如条款32所说,remove方法并不是对容器元素的直接删除,而是以填坑的方式将不应该被remove的元素移到容器的前端,这对于指针元素的容器来说将会造成被remove的指针丢失,从而造成资源的泄露。这里书上给出了两种方法,一种是在使用remove方法前,把那些应该被remove的指针做delete操作并置为0,然后调用remove去除这些为0的空指针;另一种是使用“引用计数”智能指针来管理指针,这样在remove后没有再被引用的指针将被智能指针自动删除。
1 | void delAndNullifyUncertified(Widget*& pWidget) // 如果*pWidget是一个 |
1 | template<typename T> // RCSP = “引用计数 |
条款34:注意哪个算法需要有序区间
当操作有序区间的时候最有用的算法:
- binary_search
- lower_bound
- upper_bound
- equal_range
- set_union
- set_intersection
- set_difference
- set_symmetric_difference
- merge
- inplace_merge
- includes
binary_search、lower_bound、upper_bound和equal_range使用二分查找,因此必须提供已经排过序的区间,从而获得对数时间的查找,且仅当提供的时随机访问迭代器才能保证这样的性能(由于二分查找找中心点的方法)。
set_union、set_intersection、set_difference和set_symmetric_difference也需要区间有序从而提供线性时间的性能。
merge和inplace_merge需要两个区间都有序,从而提供单遍合并排序算法。
includes需要两个区间都有序,从而提供线性时间性能。
另外unique和unique_copy的行为是“从每个相等元素的连续组中去除第一个以外所有的元素”,所以一般上需要保持传递给unique和unique_copy是有序的。
需要注意的是上述算法默认都是以升序来进行操作的,如果提供的容器区间是降序的,需要提供这个降序的比较函数。
另外上述算法里除unique和unique_copy以外都是通过等价来判断两个值是否“相同”,unique和unique_copy则是通过相等来判断。
条款35:通过mismatch或lexicographical比较实现简单的忽略大小写字符串比较
针对“怎么使用STL进行忽略大小写的字符串比较”书上给出了三个方法:
自定义字符比较函数并使用mismatch来判断字符串是否相等,对外ciStringCompare的行为保证和strcmp一致(在返回值上)
1 | int ciCharCompare(char c1, char c2) |
利用lexicographical_compare完成两个区间的逐一比较
1 | bool ciCharLess(char c1, char c2) |
或者利用系统级函数来完成这个任务
1 | int ciStringCompare(const string& s1, const string& s2) |
条款36:了解copy_if的正确实现
effective stl成书之时Mayers并不知道C++11标准中已经将copy_if作为标准放置于<algorithm>中了,所以才有了此条目。这里列下书上所写的copy_if的正确实现
1 | template<typename InputIterator,typename OutputIterator,typename Predicate> |
虽然也可以通过remove_copy_if(begin,end,destBegin,not1(p))的实现来完成copy_if的功能,但由于STL算法并不要求其仿函数为可适配的函数对象,所以上述实现较为复合STL的风格。
条款37:用accumulate或for_each来统计区间
总结下关于accumulate和for_each的使用,accmulate位于numeric头文件中,在容器的开始和结束区间参数之外还需要一个类型T的初始值作为参数,接受BinaryOperation(接受两个参数返回一个参数),accmulate最后返回一个类型T的累计值
1 | struct Point |
for_each位于algorithm内,区间参数之外接受一个统计函数对象作为参数,最后返回一个统计好的函数对象,注意入参的函数对象由于是按值传递和返回的函数对象并不是同一个
1 | struct Point |
条款38:把仿函数类设计为用于值传递
函数对象在作为参数传递的时候默认以按值传递,for_each就是个好例子,作为参数传入的函数对象和返回的函数对象不是同一个,且传入的函数对象并不发生变化。
想要按引用传递可以在模板实例化时显示声明按引用传递函数对象,例如:
1 | class DoSomething : public unary_function<int, void> |
但是某些STL实现中并不能这样写,编译无法通过。
按值传递意味着想要效率高,就必须使拷贝的代价小,同时如果传入的参数和要求的函数对象存在继承关系,会有对象的切割问题。解决这个问题可以使用Pimpl思路,即函数对象内包含其实现类指针,实现函数调用其实现类指针的实现函数。这样外层函数对象足够小易于拷贝,实现和接口隔离后也不存在继承和虚函数问题。
1 | template<typename T> |
条款39:用纯函数做判断式
强调STL算法函数接受的函数参数应该是纯函数,纯函数定义为:返回值只依赖于参数的函数。由于函数对象按值传递,每次传递都意味着函数对象的拷贝,如果该判断式的返回值会因其他变量影响而改变,将造成算法函数执行异常,书上举了个比较极端的例子:
1 | class BadPredicate : public unary_function<Widget, bool> |
由于remove_if通常实现形式如下:
1 | template <typename FwdIterator, typename Predicate> |
find_if在第三个对象时返回给begin,再对++begin到end之后的元素做remve_copy_if,其结果copy到begin及其之后,这将导致容器第三个元素及第六个元素被删除,原因是find_if和remove_copy_if使用的判断式函数对象皆为timesCalled为0的初始函数对象,这有所违背remove_if想要删除第三个的本意。给operator()方法加上const描述可以保证函数不改变其成员变量,但是无法保证其不会修改静态变量、mutable成员变量。所以判断式函数使用时应注意其是否会影响到函数具体实现,如果会那这个判断式函数必须是一个纯函数。
条款40:使仿函数类可适配
强调如果你的仿函数类需要使用not1、not2等functional方法,由于not1等方法需要argument_type、first_argument_type、second_argument_type和result_type的typedef,可以使你的仿函数类继承unary_function、binary_function来指定这些typedef。例如:
1 | template<typename T> class MeetsThreshold : public std::unary_function<Widget, bool> |
但是unary_function和binary_function在c++11中已经弃用,在C++17中删除。这是由于仅仅是typedef不足以成为继承这一is_a关系的理由,所以这一条款更多的应该是阐述,如果要使你的仿函数类可适配,你需要为你的仿函数类指定argument_type、first_argument_type等typedef。