这是个人阅读Effective STL所做的读书笔记第三部分,包含《Effective STL》条款21~条款30的笔记内容。
条款21:永远让比较函数对相等的值返回false
关联容器由于使用比较函数来判断新数据插入位置(等价思想),如果用户自定义的比较函数对相等的值返回true,将导致新插入的相等的值插入到关联容器中,对于不允许出现复本的关联容器来说已经破坏了其规则。这里书上举了一个使用less_equal作为比较方法的set的例子,形如:
1 | set<int,less_equal<int>> s; |
在第二次插入时,将遇到如下判断:
1 | !less_equal(10,10) && !less_equal(10,10) |
而这个判断将为false,即代表第二个10并不与第一个10等价,所以第二个10将插入到s中。
对于容许出现复本的关联容器来说,同样存在问题,当使用equal_range来查找元素时,由于同样使用了比较方法来进行查找,而相同的元素并不等价,例如上面这个例子中如果是multiset,第二个10就不会出现在equal_range的结果范围内。
这里提到了排序关联容器的一个概念,strict week ordering,严格的弱序话,后面有时间专门来写一篇。
条款22:避免原地修改set和multiset的值
map和multimap的key无法原地进行修改,但是可以修改其值,这是由于其元素的值是pair<const K, v>。对于set和multiset来说,由于各种stl实现的不同,某些实现的版本可能会拒绝修改其值,即使是非key的值。这里我做了下测试,使用书上的代码如下:
1 |
|
在gcc/g++ 4.8.5版本下,编译报错,
./clause_22.cpp:50:28: error: passing ‘const Employee’ as ‘this’ argument of ‘void Employee::setTitle(std::string&)’ discards qualifiers [-fpermissive]
i->setTitle(strTemp);
即set<T>::iterator的operator*返回的是const T&,所以无法直接原地修改值。
这里书上写了两种改变值的方法,一种是利用动态转换(书上的叫法是"映射"):
1 | if (i != se.end()) { |
即利用const_cast去除const T&的常量性,但是动态转换存在很多问题,并且当把这层常量型去除后可能会出现很多安全问题;
所以这里书上给出了一个安全的、可移植(针对不同的stl实现)的修改set和multiset值的方法:
1 | EmpIDSet se; // 同前,se是一个以ID号 |
条款23:考虑用有序vector代替关联容器
使用有序vector代替关联容器是有场景前提的,这里作者Meyers考虑了平时程序中使用容器时常遇到的一个场景,并将其整理总结为以下三个阶段:
- 建立,通过反复插入和删除操作建立一个容器,几乎没有查找
- 查找,这个阶段只有查找几乎没有插入和删除
- 重组,修改容器内容,删除或再插入新数据,类似于阶段1,这个阶段完成后程序又返回阶段2
对于这种场景来说,一个有序的vector会比关联容器提供更高的性能。这里理由有二,一是vector由于实现使用的是数组,关联容器通常使用二叉树来实现,二叉树在实现上通常要多出来三个指针(父节点 左孩子节点 右孩子节点),这导致vector将占用更少的内存;二是本就占用更多内存的关联容器,由于是链表的实现,其内存分布将在更分散的区域上,这导致一些基于容器之上的一些算法在便利容器时,更容易导致内存换页,也就使得性能下降。
使用vector代替关联容器时需要注意几点,map中的元素为pair<const K, V>,而vector中只能为pair<K, V>,这是因为vector的元素在移动时,其元素必须是可赋值的;map在排序时比较的是key,而pair<K,V>的默认operate <将对K和V都进行比较,所以需要提供自定义只比较K的排序方法;同时对于查找的比较函数来说需要一个key类型的对象(要查找的值)和一个pair(存储在vector中的一个pair)两个不同类型的入参,所以还需要另外提供一个比较函数。这里书上提供了一个例子:
1 | typedef pair<string, int> Data; // 在这个例子里 |
条款24:当关乎效率时应该在map::operator[]和map-insert之间仔细选择
当需要在意效率时,需要在使用map::operator[]时考虑这次操作是新增元素还是对原有元素的赋值。由于map::operator[]返回的是mapped_type&,对于取原有就存在的元素时,只需返回那个key对应的value的引用即可;但是对于不存在的key来说,将调用默认空构构造一个mapped_type返回其引用,再由mapped_type的operator=完成赋值操作。这里就存在性能上不必要的消耗:一个建立临时对象(用于做插入的临时对象)的构造与析构,和一个赋值操作。而这些消耗可以通过改由map::insert来代替而消除。这里书上给出了一个efficientAddOrUpdate的例子,即在新元素时使用insert来插入,老元素时使用operator[]来进行赋值:
1 | template<typename MapType, // map的类型 |
这里使用KeyArgType和ValueArgType而非MapType::key_type和MapType::mapped_type,是因为当不使用map中存储的类型进行插入时,是因为形如:
1 | map<int, Widget> m; |
当m中已有10这个key时,进行赋值可直接调用opeartor=来进行操作,如果使用的mapped_type作为第三类型参数,将先使用1.5来构造一个临时widget再使用其进行赋值操作,这将产生多余的构造和析构。
条款25:熟悉非标准散列容器
本节主要对SGI和STLport中散列容器进行了一些初步介绍,hash_set、hash_multiset、hash_map和hash_multimap,实际上在C++11后STL里中的对应的散列容器已经标准化(unordered_set、unordered_multiset、unordered_map和unordered_multimap),有关这部分STL内容后面会写篇文章来介绍,这里只是effective stl的笔记。
SGI中hash_set的形式形如:
1 | template<typename T, |
注意这里使用的比较方法是equal_to而非less,即使用相等的概念,这是由于散列关联容器并不需要保持有序;
Dinkmuware的实现形式形如:
1 | template<typename T, typename CompareFunction> |
使用一个HashingInfo将所需要的一些信息包含在内,用户可以选择自定义或者继承hash_compare来改变散列配置。
条款26:尽量用iterator代替const_iterator,reverse_iterator和const_reverse_iterator

引用一下书上的图,iterator可以隐式转换到reverse_iterator也可以隐式转换到const_iterator,reverse_iteartor可以隐式转换到const_verse_iterator,反果然都不可隐式转换,也就是说所有用到iterator作为参数的函数将无法直接传递const_iterator或者是reverse_iterator,reverse_iterator和const_reverse_iterator同理。这里书上举例了insert、erase方法来作为例证,事实上在C++98中insert和erase方法是传递的iterator,但是到C++11标准中insert和erase方法传递的参数已变成传递const_iterator:


部分gcc 8.0下bits/stl_list.h中的代码
1 |
|
书上提到的另外一个问题是不同种类的迭代器混用问题,形如:
1 | typedef deque<int> IntDeque; // typedef可以极大地简化 |
某些STL实现上如果const_iterator的operator==是成员函数,这将导致以上代码无法通过编译,所以需要调换==左右操作数位置:
1 | if (ci == i)... // 当上面比较无法 |
iterator隐式转换成const_iterator通过const_iterator的成员operator==函数来进行操作。
这里书上所说的减少不同类型迭代器混用个人觉得就算是C++11以上版本也是行得通的,但是在新版本C++下是否需要尽量用iterator代替const_iterator,reverse_iterator和const_reverse_iterator个人认为还是有待考量。
条款27:用distance和advance把const_iterator转化成iterator
延续上个条款中有关iterator和const_iterator转换的讨论,由于有接口只接受iterator,如果只有const_iterator就需要将const_iterator转换成iterator。这里要注意的是const_iterator是无法隐式转换成iterator的,同时如果使用const_cast来进行转换仍然可能出现问题,其原因在于虽然对于vector
这里提供了一种思路,利用distance方法计算距离再用advance得到iterator位置:
1 | typedef deque<int> IntDeque; |
由于advance的函数签名是:
1 | template<class InputIterator> |
两个参数都是同一类型,所以在distance调用时需要指明模板参数类型,否则编译无法通过。
使用这个方法需要注意的是效率问题,对于vector、string和deque来说,由于是随机访问迭代器,花费将是常数时间;对于其他双向迭代器而言,将会花费线性时间。同时这个方法还需要能访问原迭代器的对应容器。
条款28:了解如何通过reverse_iterator的base得到iterator
如条款26所说,reverse_iterator可以调用其base方法得到iterator,但是这里需要注意这里存在指向的偏差,书上用了一个很好的图来标识这个指向偏差:
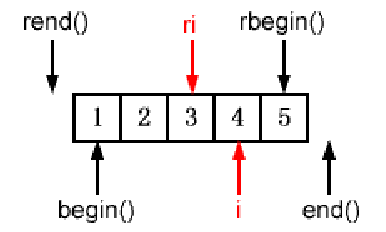
这里写了个测试程序来验证这个偏移:
1 |
|
程序输出:
begin:1
end:0
rev_begin:9
rev_end:0
rev_begin_base:0
rev_end_base:1
iter:4
revIt:3
revIt.base():4
revIt:4
revIt.base():5
也就是iterator隐式转换到reverse_iterator的时候,其指向会逆向+1,调用reverse_iterator的base方法得到的iteartor指向将是按iteartor的正向+1。
这将影响到reverse_iteartor转换到iterator后iterator的使用,这里书上详述了插入和删除时的场景。
对于插入来说,形如1 2 3 4 5的vector,当reverse_iterator指向3时,这时在3这个位置上插入整数99,按照当前逆序的思维,3位置上赋值99并将其后的3 2 1数据整体后移,将得到形如1 2 3 99 4 5的vector;当reverse_iterator使用base转换为iterator时,将得到一个指向4的iterator,这时在这个iterator上插入整数99,按照正序的思维4的位置上赋值99,将其后的数据4 5整体后移,将得到形如1 2 3 99 4 5的vector;从结果上来看这两种思维是一致的,所以书上指明在插入时,reverse_iterator和reverse_iterator.base()是等价的。
对于删除来说,就不一样了,由于指向的偏差,如果不做特殊处理其删除的元素会出现偏差。这里书上建议了一种操作方式:
1 | vector<int> v; |
而以下这种形式
1 | v.erase(--ri.base()); |
由于ri.base()从实现上可能会直接返回指针,对指针直接进行操作可能会因为容器内部的数据长度问题而引发指向问题,所以较为安全的方法还是前者。
条款29:需要一个一个字符输入时考虑使用istreambuf_iterator
当需要一个一个字符进行输入时,使用istream_iterator来读取字符:
1 | ifstream inputFile("interestingData.txt"); |
书上提供了stl里的另一个思路:
1 | ifstream inputFile("interestingData.txt"); |
对比使用istream_iterator来读取,istream_iterator使用operator>>来读取每个字符,为了保证operator>>的正常工作和异常处理需要更多的一些操作;而istreambuf_iterator<char>对象从istream s读取只调用s.rdbuf()->sgetc()来读取s的下一个字符,从而有效率上的优势,但这种优势也会随着stl实现上的改变而缩小;
条款30:确保目标区间足够大
本条款的关注点在于,当使用一个需要指定目标区间的算法时,确保目的区间已经足够大可以容纳下算法增加的元素,这里书上举了transform的例子。当从一个容器transform元素到另一个容器对应位置时,需要确保目的容器能够容纳下新增元素,这里书上给出了在目的容器头、尾、任意位置插入新增元素的例子:
1 | vector<int> values; |
1 | list<int> results; |
1 | vector<int> values; |
其中back_inserter使用容器的push_back方法来插入新元素,所以需要容器提供push_back方法,即标准容器中的vector,deque以及list;front_inserter使用push_front方法来插入新元素,标准容器中只有deque和list提供;inserter使用insert方法,大部分标准容器都提供该方法。
或者覆盖原容器内容:
1 | vector<int> values; |
无论何时你使用一个要求指定目的区间的算法,确保目的区间已经足够大或者在算法执行时可以增加大小,如果你选择增加大小,就使用插入迭代器。